21-й сборник рецептов. В нем мы научимся отправлять сообщения в Telegram прямо из A-Parser, изучим работу с модулями Node.js в JS парсерах на примере решения задачи фильтрации по множеству признаков, а также спарсим весь IMDb. Поехали!
Уведомления в Telegram из A-Parser
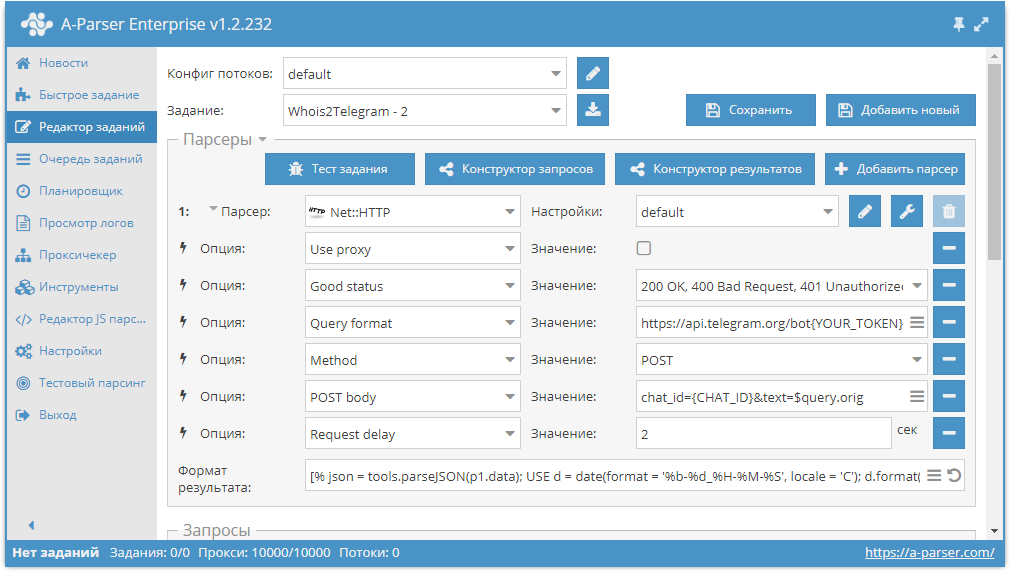
Telegram является одним из самых популярных мессенджеров благодаря своей простоте, и в то же время большому функционалу. Среди прочего, в Телеграме можно создавать ботов, с помощью которых можно делать чаты более интерактивными. Взаимодействие с ботом на на стороне сервера происходит через Telegram Bot API. Используя эти возможности, можно легко и буквально за несколько минут настроить уведомления себе в Telegram прямо из парсера. О том, как это сделать, а также несколько реальных примеров - по ссылке выше.


Фильтрация по множеству признаков
Как известно, для фильтрации в А-Парсере используется встроенный функционал фильтров. Но бывают ситуации, когда список признаков, наличие которых нужно проверять, очень большой и его сложно вписать в строку стандартного фильтра.
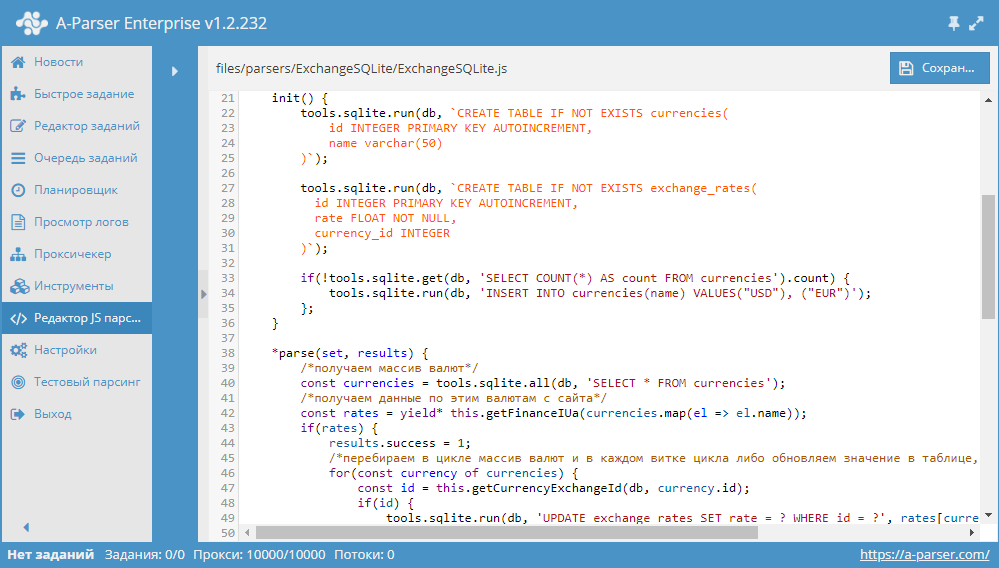
Начиная с версии 1.2.127 в A-Parser добавлена поддержка модулей Node.js. Благодаря этому появилась возможность читать список признаков из файла и использовать его для проверки страниц. О том, как это сделать, а также готовый парсер с мультифильтром - по ссылке выше.
Парсинг рекомендаций фильмов из IMDb
Пример решения задачи по сбору данных о фильмах и их рекомендаций на IMDb. Данная статья показывает, как можно решать задачи, которые на первый взгляд требуют много времени и ресурсов, буквально за несколько часов. Узнать о том, как спарсить весь IMDb за 1,5 часа, а также посмотреть пресет и забрать готовую базу можно по ссылке выше.
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь нанаш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
Сборники статей:
- Сборник статей #1: A-Parser для маркетологов, SEO-специалистов и реальный опыт работы
- Сборник статей #2: цикл статей-уроков по созданию JS парсеров